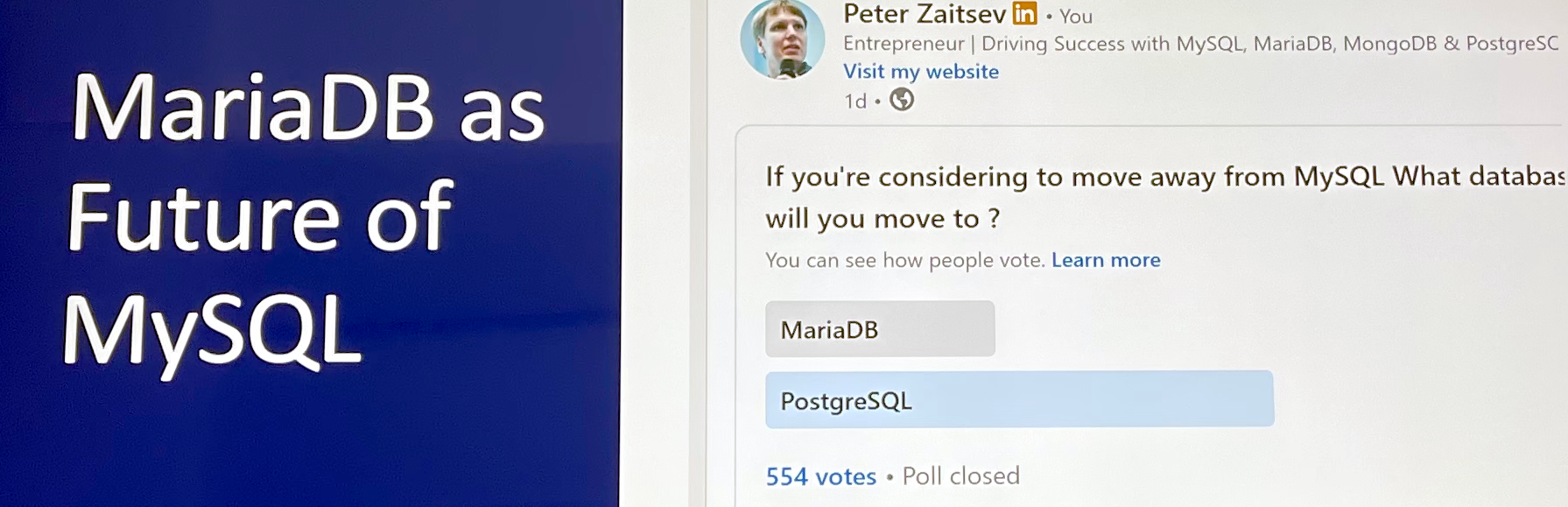
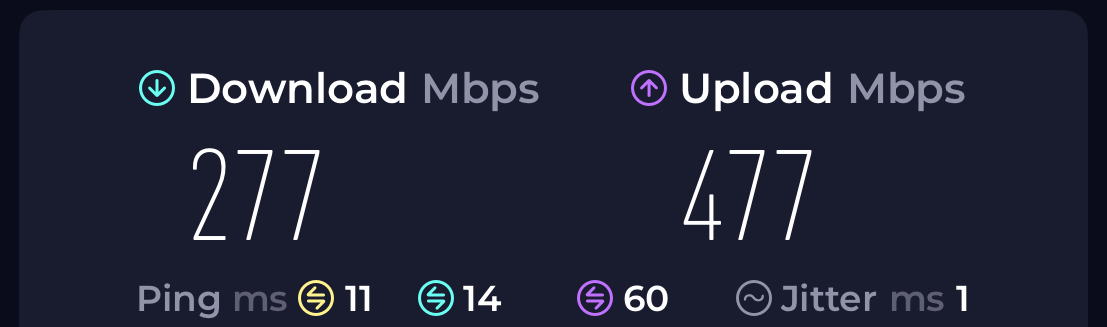
Commentary
Databases
Conferences
Open Source
Is MySQL Due for a Renaissance?
Commentary
Stuff
New Laptop
Commentary
Open Source
Happy Anniversary: Revisiting the AGPL and CLAs
Commentary
Tips and Tricks
Internet of Things
Home Assistant and DNS
Commentary
People
Billie the Platypus
Conferences
2025 re:Invent - How AWS Stole Christmas
Travel
Zürich and Vaduz
Conferences
NixCon 2025
Commentary
Stuff
It's Always a Physical Layer Problem
Programming
GenAI
Introducing hugo-planet
1
2
…
121