I traveled for much of the last two months and during that time I went to four conferences. I usually like to write about them when they are happening but I wasn’t able to manage it, so I’m offering them up a little delayed. I’m going to start with the last one, which was the Coalesce conference hosted by dbt Labs.
I’m a big dbt Labs fan, as they create a ton of useful open source software focused mainly on the “T” part of ETL. I went to their conference last year, which was in San Diego, and it was a lot of fun, but I must be honest in that when they announced it would be in Las Vegas this year I was not that excited.
I get my fill of Vegas at the annual AWS re:Invent conference, and while I’ve met a lot of friendly residents in that town it is not a favorite. I don’t often gamble, and I don’t like crowds or rampant commercialism. Vegas does have decent food options.
That said, I rather enjoyed this trip. The conference was held at Resorts World, which is a Hilton-owned property, and I stayed in the Conrad tower. While I have zero status at Hilton I got a nice room at a reasonable price, and it was great to be able to return to it just by taking an elevator. The conference was on the second floor, while the ground floor hosted a number of events held in various restaurants and bars (as well as being the location of the main casino). I didn’t leave the building for over two days.
I arrived Monday mid-afternoon and that was a day set aside for partner meetings. AWS was well represented and Yev Kravchenko and Siva Ragahupathy did a nice presentation on modern data foundations using dbt and AWS.

That evening the expo floor opened up. One nice thing about being in Vegas is they know hospitality, and the snacks and drinks were top notch. Outside of keynotes, wandering around the expo is one of my favorite parts of any conference.
Since AWS had so many people there, we all got together for dinner. I think there were 12 of us at the table. It was nice to spend time old friends and to make some new ones. One thing I love about working at AWS is being around people who are so much smarter than me.
The next morning the conference officially started. My admission included breakfast and lunch, so I went down to the second floor for food. I liked to sit towards the back of the area next to the windows so I could get a view of The Sphere.

I thought it was funny that Resorts World also had a sort of mini-Sphere:

The main theme of the conference was “One dbt“, reflecting the goal of “an integrated, governed, and scalable approach to data analytics”.

dbt Labs has two main products: the open source “dbt Core” and the managed offering “dbt Cloud”. A goal of One dbt is to make it much easier to work with and switch between them. For example, production could run on cloud due to the extra security and reliability but development could be done locally on core.
Tuesday’s keynote introduced us to our hosts for the week: Lesley Greene, Grace Goheen and Alexis Jones.

They welcomed us to the conference and pointed out that there were around 2000 people in attendance and another 8000 or so watching virtually. They also thanked the sponsors, and AWS joined Tableau and Snowflake at the platinum level.

Alexis then introduced the first speaker, co-founder and CEO Tristan Handy.

He talked about the origins of dbt Labs, which began life as Fishtown Analytics (Fishtown is a section of Philadelphia, PA, USA, where the company was founded) with its mission to create a mature workflow system for analytics. This has now grown into something they are calling the “data control plane”:

He also announced “dbt Copilot”, a generative AI product to leverage genAI models to help write code, analyze logs, improve query performance and use natural language to ask business questions.
Tristan then brought out Yannick Misteli, who is the head of engineering at Roche. He talked about their five year journey with dbt because they needed to build a world class analytics platform and dbt “checked all the boxes”.

The next presentation brought back an old Coalesce favorite, The Jaffle Shop. The Jaffle Shop is an example company created to demonstrate practical uses for dbt Labs’ products, and this year they were expanding. Since a lot of their sales occurred at venues, they decided to buy one: Cirque du Jafflé.
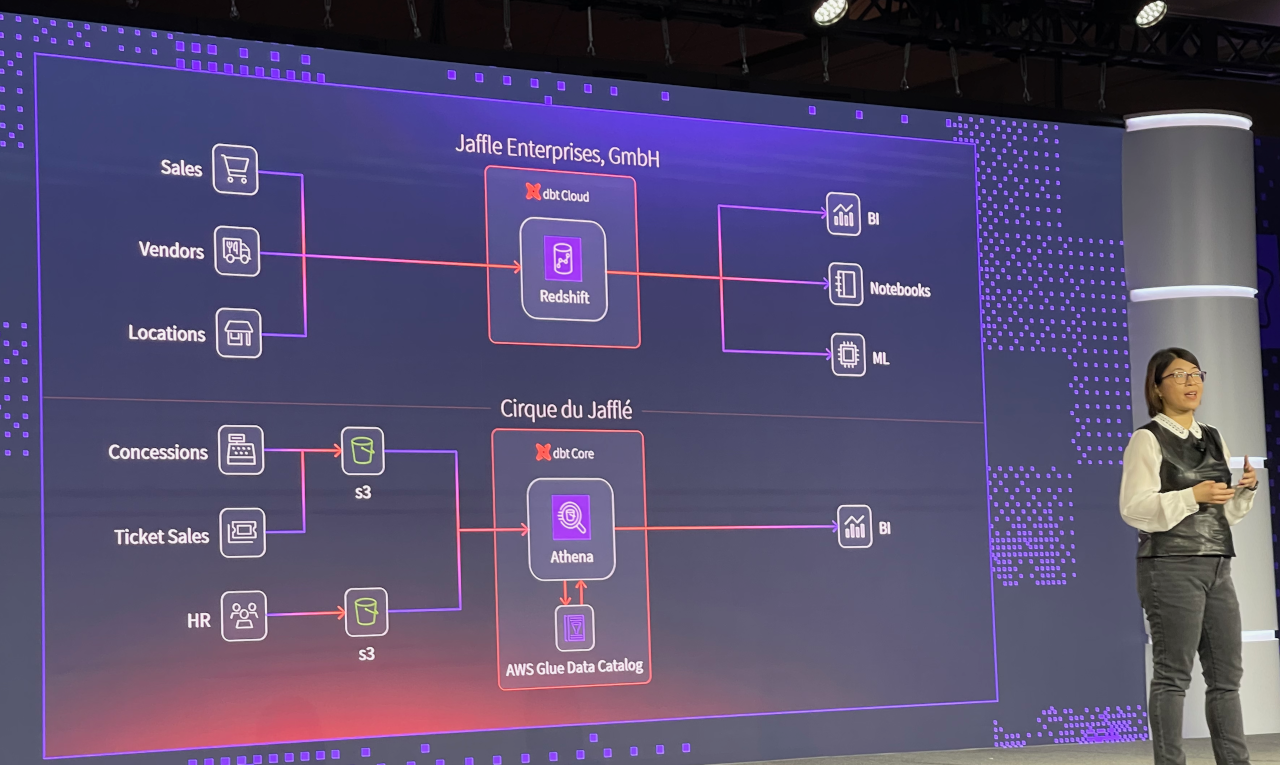
Amy Chen walked us through how one would take two discrete organizations, both who were using dbt products, and combine them. In this hypothetical example, The Jaffle Shop used dbt Cloud with data in Amazon Redshift while Cirque du Jafflé used dbt Core over Amazon Athena.
dbt Cloud now supports a dbt to Athena connector, so it is a somewhat trivial exercise to access that data, and Amy did a great job with the example to show how to do it.
The next guest speaker was Tobi Humpert from Siemens.

Amy broke the ice by bringing up the fact that at the Munich location, Siemens uses sheep to keep the lawn at the proper height, versus mowing it. These sheep are removed in the winter and return the following spring, and this was a segue into cross platform lineage (if you had lineage you would know where they went). Of course the talk then moved into more practical for cross-platform data, enabled by dbt Mesh.

Amy then handed the floor over to Greg McKeon to talk about a new visual editor available in dbt Cloud. He did a demo which also included an integration with dbt Copilot, which involved adding tests and documentation to an existing dbt model.

Greg was followed by Roxi Dahlke, who talked about how to maintain high-quality data you can trust during transformation.

This is done through three new dbt features: Advanced CI (Continuous Integration), Trust and Usage Signals (how data is consumed and is it trustworthy), and the Semantic Layer (custom system metrics across all tools). She also did a dbt Copilot demo leveraging the existing semantic layer to allow for natural language queries.

Roxy invited a special guest, James Dorado from Bilt Rewards, who discussed how they were using the semantic layer to present data directly to end customers, which requires even more trust in that data then we you use it internally.

For the final part of the keynote, Tristan returned to discuss how dbt partners were supporting analytics workflows from end-to-end and it featured Dan Jewett from Tableau and Neeraja Rentachintala from AWS. The discussion focused on how the new product announcements were going to improve the customer experience.
Overall I enjoyed the keynote and I saw a real natural progression for dbt as it continued to focus on making analytics workflows more powerful, more relevant to business needs, and easier to use.
Outside of the keynotes, Coalesce provided a lot of other sessions. I don’t directly use dbt so many (most) of them were above my head, but I did attend all of the ones by AWS folks.

The first one was a talk by Darshit Thakkar and BP Yau called “Amazon Athena and dbt: Unlocking serverless data transformations”.

I understood a lot of this, and I know that “serverless” is becoming the preferred way to manage cloud resources, but I did have a problem with the demo. BP likes to use dark mode. I’m not a fan. I grew up reading dark text on a light background so that is my preference, but in this case it made it almost impossible to see the text on the projection screen, so I just took his word for it (grin).

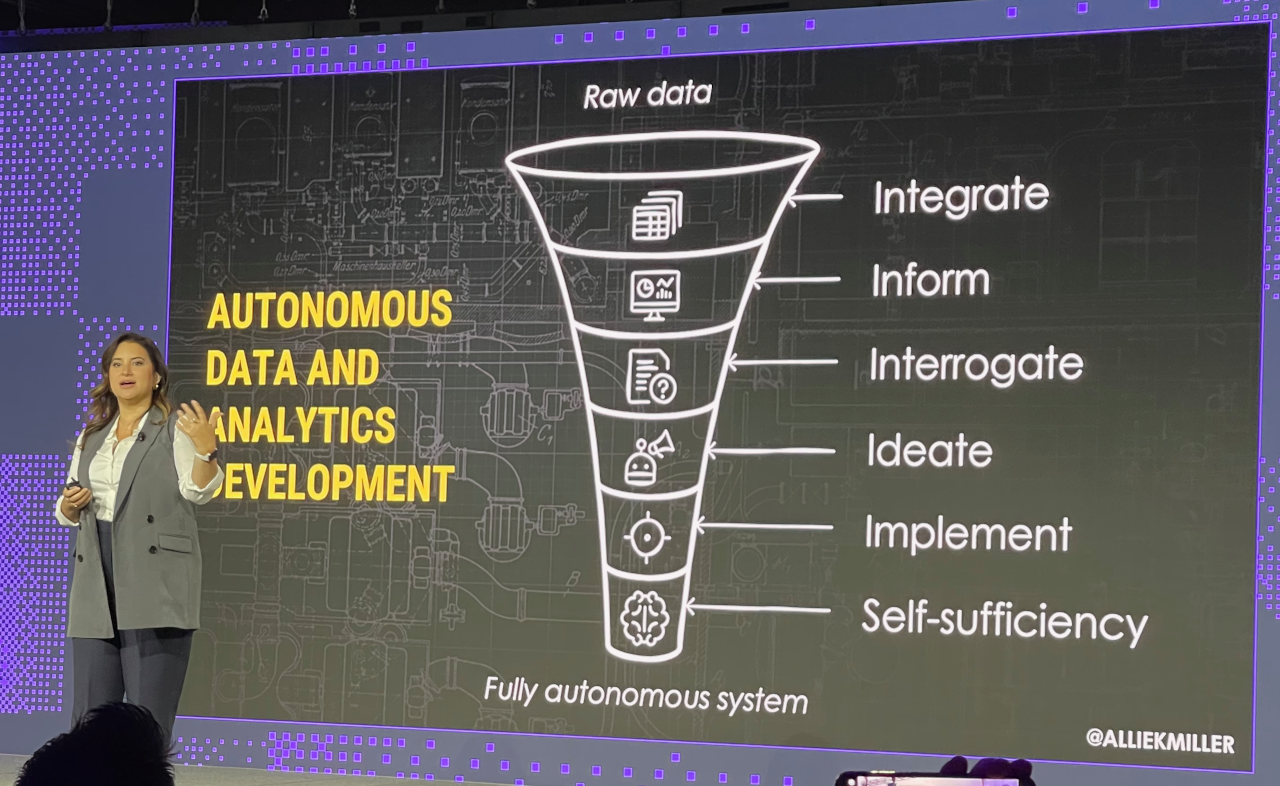
The Wednesday morning keynotes kicked off with a presentation by Allie K. Miller on artificial intelligence. GenAI is such a hot topic in the industry that you can’t go to any conference these days without encountering it. While I’m at the edge of burnout on the topic, I did enjoy her presentation, which included a graphic on the progression of true autonomous analytics.
She also sent a link to a cool use of genAI where it takes a picture and turns it into kind of a squishy play-dough kind of thing, that I found fascinatingly weird.

This was followed by a customer panel lead by Brandon Sweeney, featuring Kayleigh Lavorini from Fifth Third Bank and Srini Vemuru from Salesforce. The discussion involved their thoughts for using AI for their analytics needs and how they leverage dbt.

As my focus is open source, I was drawn to any presentation involving dbt Core, and one of the more amusing ones was given by Grace Goheen. I had met Grace and Jeremy Cohen at one of the casino bars the night before, and they are both theatre nerds (spoken as an ex-theatre nerd myself). Jeremy currently lives in France (and he was the only one to pronounce “Cirque du Jafflé” in the proper accent) and he made a cameo as Elvis (we were in Vegas, after all). I expect some sort of “rat pack” reference next year. (grin)

To be serious for a moment, all of us in the open source community have witnessed established projects making big changes in their licenses over the last couple of years. While I don’t want to comment on that in this post, it is always nice to see folks like dbt confirm that they have no plans to change the license on dbt Core. I’ve heard it from the top, including Tristan and Mark Porter, and in this presentation Grace renewed that vow in the form of a “wedding” officiated by Elvis.
It was a cute and entertaining way of addressing a very serious subject.

There was another session by AWS speakers Wednesday afternoon with the lofty title of “Journey to Generative AI driven near-real-time-operational analytics with zero-ETL and dbt Cloud”. Whew.

This was presented by Neerja Rentachintala (who you may remember from the Tuesday keynote) and Neela Kulkarni. They presented a reference architecture built on Amazon Aurora, Amazon Redshift and dbt Cloud for operational analytics.
Neela did the demo, and I am happy to say she used both light mode and a large typeface so I could see what she was doing. That doesn’t mean that I totally understood what she was doing, but the audience seemed to get it. (grin)
Wednesday night was the Coalesce party, and as I’ve mentioned before Vegas is known for its hospitality industry so it was top notch. Held in one of the nightclubs in Resorts World it featured a DJ, lights, lots of food and drink.
I am not one for large crowds so I didn’t stay very long. In fact, I had been traveling for almost six weeks straight so I ended up finding a flight home that still allowed me to attend Thursday’s keynote. The people I talked to who stayed at the party had a great time, and it seemed like the attendees enjoyed it.
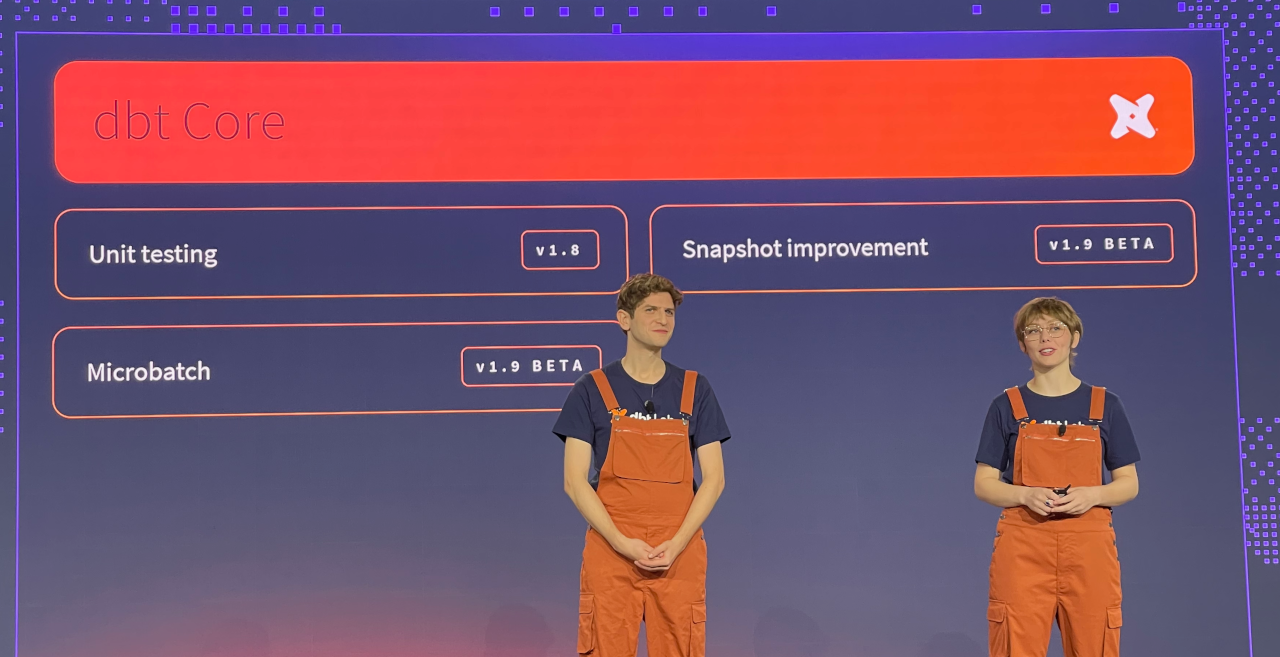
Thursday’s keynote focused on dbt Core and the community, and was hosted by Grace and Jeremy, along with Amada Echeverría presenting the Community Awards.
While a lot of the focus of the keynotes was on dbt Cloud, this one focused on all of the work that is being done in dbt Core, including a feature to unit test dbt models, improvements to snapshots, as well as the the ability to do “microbatches” which allows a user to break up large datasets into smaller chunks for processing.

Then it was time for the Community Awards.

I was extremely happy to see my friends on the dbt-athena adapter get the Trailblazing Innovator award. Last year at Coalesce, my boss David Nalley made a special reference to this team, made up of Jérémy Guiselin, Nicola Corda, Jesse Dobbelaere, Mattia Sappa, and Serhii Dimchenko, who had created an adapter that was so well made it achieved, this year, “trusted” status and, as was mentioned above, is now supported in dbt Cloud as well as dbt Core.

Three of the award winners, Influencer Extraordinaire Opeyemi Fabiyi, Data Governance Excellence winner Jenna Jordan and Catalyst of Impact winner Bruno Souza de Lima, were in attendance and participated in a panel discussion on the rewards and challenges of their work in the community.

The final part of keynote brought our hosts back out to talk about Coalesce 2025, which will be back in Las Vegas on 6-9 October.
As reluctant as I was to consider another Vegas conference, I have to say that the Resorts World location really worked for Coalesce, and I look forward to returning for my third event next year.
[Note: if you are part of an open source startup, or want to start an open source company, and you are coming to re:Invent, be sure to attend this panel featuring Tristan Handy]